MNIST
MNIST handwritten digit database, Yann LeCun, Corinna Cortes and Chris Burges
yann.lecun.com
MNIST(Modified National Institute of Standard and Technology) 데이터셋에는 손으로 쓴 숫자의 이미지와 각 이미지에는 어떤 숫자인지 알려주는 테이블이 붙어 있다. 레이블에는 필기체 숫자에 따라 0~9 사이의 값이 들어 있어 10종류로 분류될 수 있는 숫자 이미지 70,000개가 들어 있다. 각 이미지는 회색조(grayscale)로 되어 있고 28 X 28 픽셀로 구성됐고 0~255사이의 숫자 행렬로 표현되어 있다.
텐서플로 2.0을 사용하여 MNIST 필기체 숫자를 인식하는 간단한 신경망을 만들어서 점진적으로 개선해 보도록 하자. 크게 다음 순서로 신경망 모델이 만들어 지게 된다. 여기에서는 10종류의 숫자에서 0과 1의 숫자만 이미지를 뽑아서 2개만 분류하도록 한다.
1. 데이터셋 로드
2. 데이터 분할
- 훈련 집합 x_train, y_train
- 테스트 집합 x_test, y_test
- train과 test 데이터 분할은 8:2 비율로 분할
- 0과 1만 적혀 있는 숫자 이미지만 추출
3. 모델 정의 생성
4. 모델 컴파일
5. 모델 훈련
6. 모델 평가 / 검증
☑️ 데이터셋 로드 & 분할
import tensorflow as tf
from PIL import Image
import matplotlib.pyplot as plt
# mnist 손글씨 이미지 데이터 불러오기
(x_train, y_train), (x_test, y_test) = \
tf.keras.datasets.mnist.load_data()Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz
11490434/11490434 [==============================] - 2s 0us/step
y변수 학습용 데이터 구조 확인 : 숫자 종류
y_trainarray([5, 0, 4, ..., 5, 6, 8], dtype=uint8)
x변수 학습용 데이터의 구조 확인 : 6만개의 숫자 이미지가 가로 28 X 세로 28 픽셀로 구성
x_train.shape(60000, 28, 28)
x_train 학습용 데이터 중 첫번째(0) 이미지가 어떻게 생겼는지 시각화 확인 (PIL라이브러리 이용)
Image.fromarray(x_train[0])
x_train 학습용 데이터 중 첫번째(0) 이미지가 어떻게 생겼는지 시각화 확인 (matplotlib 이용)
plt.imshow(x_train[0], cmap='binary')
2보다 작은 수의 이미지만 추려내기
# 0과 1만 추리기
x_train2 = x_train[y_train < 2]
y_train2 = y_train[y_train < 2]
# 추려진 이미지 확인해 보기 (첫번째 이미지 선택)
Image.fromarray(x_train2[0])
# 추려진 이미지 확인해 보기 (열번째 이미지 선택)
Image.fromarray(x_train2[10])
☑️ 모델 정의 및 생성
import tensorflow as tf
to_flatten = tf.keras.layers.Flatten()
to_dense = tf.keras.layers.Dense(1, activation='sigmoid')
model = tf.keras.Sequential([to_flatten, to_dense])
z = to_flatten(x_train2)
z
<tf.Tensor: shape=(12665, 784), dtype=uint8, numpy=
array([[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]], dtype=uint8)>• 이미지 크기 : 28 X 28 = 784
• Sequential : 순서대로 층을 쌓아서 모델을 만드는 함수
• Flatten : 입력이 가로 ×세로 2차원 형태이므로 Flatten을 이용해 1차원 형태로 바꿈 (이미지 → 벡터로 변환)
• Dense : 모든 입력에 가중치를 곱하여 더함
- Dense가 1일 경우, 그림 하나를 0 또는 1로 분류하므로 출력의 개수는 1개를 의미함
▣ Flatten Layer
이미지 데이터는 3차원 배열로 들어온다. flatten은 그림수는 그대로 두고 가로, 세로 픽셀을 한 줄 형태로 변화시켜 2차원 배열로 바꾼다. 이것은 그 뒤에서 받는 Dense계산에서 행렬곱 계산이 가능하게 하기 위함이다.
▣ Dense Layer
• 선형 모형 y = wx + b 형태의 레이어이다.
• 모든 입력에 가중치(weights)를 곱하여 계산한다.
• Fully Connected 라고도 한다.
• 활성화 함수를 붙여 비선형적인 출력을 한다.

정의한 모델에 훈련데이터를 넣어서 어떤 형태로 결과가 나오는지 확인해보기
h = model(x_train2)
h
<tf.Tensor: shape=(12665, 1), dtype=float32, numpy=
array([[9.7179520e-01],
[8.2226543e-12],
[9.5479041e-36],
...,
[9.9987137e-01],
[3.3346766e-16],
[6.1971933e-04]], dtype=float32)>Dense를 1로 설정했기 때문에 12226개의 각각에 1개의 값을 도출해내고 시그모이드(sigmoid)함수를 통하기 때문에 0~1 사이의 값을 도출한다. 즉, 0과 1 사이의 값으로 나온다는 것은 확률로도 판단할 수 있게 되는 값이 되는 것이 된다. 활성화함수(Activation Function)을 어떤 것을 사용하느냐에 따라서 출력값의 범위가 결정된다. 정의한 모델이 어떻게 작동하는지 보았으니 이제는 모델이 컴퓨터가 실제로 계산할 수 있게 바꿔주는 것이 컴파일인데, 컴퓨터가 계산할 때, '이런 방식으로 계산해라'라고 정확하게 계산하라는 설정을 해준다. 즉, 모델이 학습을 하는 정확도를 평가하며 지도해 주는 설정이라 할 수 있다.
☑️ 모델 설정
model.compile(loss='binary_crossentropy', metrics=['accuracy'])
• loss function(손실함수) : 예측이 부정확한 정도를 평가하는 방법
• binary_crossentropy : 이항분류 문제에 사용하는 파라미터로 평가가 나쁠수록 점수가 확 내려가고 좋으면 확 올라감
(2개만 분류하는 것을 이항분류, 3개부터는 다항분류로 sparse_categorical_crossentropy를 사용함)
• metrics (측정치) : 모델 성능을 참고하기 위한 지표. 훈련 과정에 직접적으로 영향은 없음
이렇게 설정을 했으니 그 다음에는 실제 훈련용 데이터를 모델에 넣어서 컴퓨터가 학습 계산을 할 수 있게 하면 된다.
☑️ 모델 훈련 (학습 데이터 이용)
model.fit(x_train2, y_train2, epochs = 10)Epoch 1/10
396/396 [==============================] - 1s 2ms/step - loss: 0.6942 - accuracy: 0.9835
Epoch 2/10
396/396 [==============================] - 1s 2ms/step - loss: 0.0906 - accuracy: 0.9976
Epoch 3/10
396/396 [==============================] - 1s 1ms/step - loss: 0.0779 - accuracy: 0.9979
Epoch 4/10
396/396 [==============================] - 1s 1ms/step - loss: 0.0430 - accuracy: 0.9990
Epoch 5/10
396/396 [==============================] - 1s 2ms/step - loss: 0.0385 - accuracy: 0.9985
Epoch 6/10
396/396 [==============================] - 1s 1ms/step - loss: 0.0390 - accuracy: 0.9986
Epoch 7/10
396/396 [==============================] - 1s 2ms/step - loss: 0.0306 - accuracy: 0.9987
Epoch 8/10
396/396 [==============================] - 1s 1ms/step - loss: 0.0282 - accuracy: 0.9992
Epoch 9/10
396/396 [==============================] - 1s 2ms/step - loss: 0.0181 - accuracy: 0.9991
Epoch 10/10
396/396 [==============================] - 1s 2ms/step - loss: 0.0172 - accuracy: 0.9994
• batch : 한 번에 모델의 파라미터 조정에 사용하는 데이터(기본 32개)
• epoch : 전체 데이터를 한 번 처음부터 끝까지 훑는 과정
• 12665 / 32 = 396 → 32로 나눠서 396개씩 10번 수행함, 기본옵션이 32로 되어 있음. 8의 배수로 늘려봐도 됨
• 에포크가 계속될수록 loss가 줄어드는 쪽으로, 정확도(accuracy)가 증가하는 쪽으로 최적 모델을 찾아감
학습된 모델이 나왔으니까 이제는 테스트용 데이터를 모델에 넣어 봐서 결과값이 예상대로 잘 예측했는지에 대해서 평가를 해보는 것이다.
☑️ 모델 평가 (테스트 데이터 이용)
# test 데이터에서 0,1값만 가져오기
x_test2 = x_test[y_test < 2]
y_test2 = y_test[y_test < 2]
model.evaluate(x_test2, y_test2)67/67 [==============================] - 0s 1ms/step - loss: 0.0116 - accuracy: 0.9995
[0.011588851921260357, 0.9995272159576416]
참고로 파라미터 확인은 아래와 같이 확인해 본다.
weight, bias = model.trainable_weights

• 784의 1차원 이미지 벡터에 일일이 위와 같은 weight를 곱해준 것을 알 수 있다
☑️ 모델 예측 (테스트 데이터 이용)
model.predict(x_test2)67/67 [==============================] - 0s 1ms/step
array([[1.],
[0.],
[1.],
...,
[1.],
[0.],
[1.]], dtype=float32)
모델에 넣은 결과값이 확률값이기 때문에 정수로 바꿔준다. 값이 0.5보다 크면 1로 간주하고, 작으면 0으로 간주하려고 한다. 물론 확률을 딱 잘라서 0과 1로 편입시킬 수는 없지만 판단하기 좋게 편의상 그렇게 하는 것이다. 그런데 우리가 여기에서 손글씨 이미지를 숫자 0과 1이 적힌 두 가지 종류의 숫자 이미지만 가지고 판단하는 것이므로 확률이 0에 가까우면 숫자 0을 말하고, 확률 1에 가까우면 숫자 1을 말할 수 있다. 두 가지를 분류하는 이항분류가 아닌 3가지 이상의 요소를 분류하는 다항분류는 항목별로 가장 높은 확률을 가지고 맞췄는지 틀렸는지 평가하게 된다.
prob = model.predict(x_test2)
y_pred = np.where(prob > 0.5, 1, 0)
y_pred67/67 [==============================] - 0s 1ms/step
array([[1],
[0],
[1],
...,
[1],
[0],
[1]])
테스트 데이터의 2번째 숫자가 0인데, 예측한 결과의 2번째 값도 0 이다.
Image.fromarray(x_test2[1])
테스트 데이터의 3번째 숫자가 1인데, 예측한 결과의 3번째 값도 1 이다.
Image.fromarray(x_test2[2])
MNIST라는 주어진 데이터 안에서 분류를 잘 하는지에 대해 모델 성능을 판단했는데 내가 적은 글씨도 잘 판단하는지는 모르는 일이다. 물론 다른 누가 쓴 글씨도 잘 알아 맞출 수 있는지도 알 수가 없기 때문에 먼저 내 손글씨 숫자 이미지를 직접 그려서 모델에 넣어 판단하게 해보도록 하자.
☑️ 모델 검증 : 직접 그린 숫자로 모델 확인
🎨 그림판에서 숫자 이미지 수작업으로 만들기
가로와 세로 픽셀을 동일하게 28x28로 해주고 배경색은 검은색으로 하고 글씨는 흰색으로 하여 숫자를 그린다.


🎨 직접 만든 숫자 그림을 불러오기
img_hand = Image.open('hand.png').convert('L')
img_hand
🎨 그림을 행렬 데이터로 바꿔주기
x = np.array(img_hand)
x.shape(28, 28)👉 훈련 데이터는 (N, 28, 28) 형태(N은 데이터 개수), x는 (28, 28) 형태이므로 0번 차원을 추가해서 (1, 28, 28) 형태로 맞춰 줘야 함
x = np.expand_dims(x, 0)
x.shape(1, 28, 28) 🎨 모델에 넣어서 어떤 값으로 예측하는지 확인
model.predict(x)1/1 [==============================] - 0s 23ms/step
array([[0.]], dtype=float32)👉 0 으로 예측이 잘 되었음을 알 수 있음
모델을 학습하여 생성하는데 성능이 향상되지 않거나 원하는 모델이 잘 나오고 있으면 굳이 계속 학습할 필요가 없기 때문에 시간낭비할 필요가 없다. 그래서 모델 학습을 지속할지 말지에 대한 판단을 학습 도중에 걸어줄 수가 있다.
🎲 얼리스톱핑 : Early Stopping
모델 적합 중에 검증 데이터로 검증하여 성능이 향상되지 않으면 진행을 중단시킬 수 있다. 미리 정한 에포크보다 일찍 멈추게 되어 과대적합을 방지하기 위한 정규화 방법으로 이용한다.

model.fit(x_train2,
y_train2,
epochs = 100,
validation_split = 0.1,
callbacks = [tf.keras.callbacks.EarlyStopping()])👉 validation_split = 0.1 : 10%의 데이터를 검증에 사용(훈련에는 제외)
Epoch 1/100
357/357 [==============================] - 1s 2ms/step - loss: 0.0143 - accuracy: 0.9992 - val_loss: 2.8961e-15 - val_accuracy: 1.0000
Epoch 2/100
357/357 [==============================] - 1s 2ms/step - loss: 0.0040 - accuracy: 0.9996 - val_loss: 2.7371e-13 - val_accuracy: 1.0000
🎲 model check point : 모델체크포인트
모든 에포크마다 결과 모델을 PC저장해 두고 안 좋아지면 다시 돌아가게 하는 방식이다. 얼리스톱핑은 조금만 느려져도 바로 수행을 멈추기 때문에 멈추지 않고 가장 좋은 모델을 취사선택할 수 있도록 할 수 있기 때문에 요즘에는 '모델 체크 포인트'를 많이 사용한다.
모델체크포인트 이용
to_flatten = tf.keras.layers.Flatten()
to_dense = tf.keras.layers.Dense(1, activation='sigmoid')
model = tf.keras.Sequential([to_flatten, to_dense])
model.compile(loss='binary_crossentropy', metrics=['accuracy'])
model.fit(x_train2,
y_train2,
epochs = 100,
validation_split = 0.1,
callbacks = [tf.keras.callbacks.ModelCheckpoint('n{epoch:02d}')])Epoch 1/100
357/357 [==============================] - ETA: 0s - loss: 0.4125 - accuracy: 0.9878INFO:tensorflow:Assets written to: ngv01\assets
357/357 [==============================] - 2s 4ms/step - loss: 0.4125 - accuracy: 0.9878 - val_loss: 0.0213 - val_accuracy: 0.9984
Epoch 2/100
346/357 [============================>.] - ETA: 0s - loss: 0.0979 - accuracy: 0.9968INFO:tensorflow:Assets written to: ngv02\assets
357/357 [==============================] - 1s 4ms/step - loss: 0.1012 - accuracy: 0.9968 - val_loss: 0.0364 - val_accuracy: 0.9984
Epoch 3/100
345/357 [===========================>..] - ETA: 0s - loss: 0.0829 - accuracy: 0.9981INFO:tensorflow:Assets written to: ngv03\assets
357/357 [==============================] - 1s 3ms/step - loss: 0.0803 - accuracy: 0.9982 - val_loss: 0.0056 - val_accuracy: 0.9992
Epoch 4/100
350/357 [============================>.] - ETA: 0s - loss: 0.0594 - accuracy: 0.9979INFO:tensorflow:Assets written to: ngv04\assets
357/357 [==============================] - 1s 3ms/step - loss: 0.0583 - accuracy: 0.9980 - val_loss: 0.0036 - val_accuracy: 0.9992
Epoch 5/100
343/357 [===========================>..] - ETA: 0s - loss: 0.0218 - accuracy: 0.9993INFO:tensorflow:Assets written to: ngv05\assets
357/357 [==============================] - 2s 4ms/step - loss: 0.0295 - accuracy: 0.9991 - val_loss: 4.4414e-11 - val_accuracy: 1.0000
Epoch 6/100
332/357 [==========================>...] - ETA: 0s - loss: 0.0315 - accuracy: 0.9988INFO:tensorflow:Assets written to: ngv06\assets
357/357 [==============================] - 1s 3ms/step - loss: 0.0321 - accuracy: 0.9986 - val_loss: 0.0029 - val_accuracy: 0.9992
Epoch 7/100
356/357 [============================>.] - ETA: 0s - loss: 0.0229 - accuracy: 0.9989INFO:tensorflow:Assets written to: ngv07\assets
357/357 [==============================] - 1s 3ms/step - loss: 0.0229 - accuracy: 0.9989 - val_loss: 1.0574e-16 - val_accuracy: 1.0000
Epoch 8/100
330/357 [==========================>...] - ETA: 0s - loss: 0.0083 - accuracy: 0.9993INFO:tensorflow:Assets written to: ngv08\assets
357/357 [==============================] - 1s 3ms/step - loss: 0.0080 - accuracy: 0.9993 - val_loss: 0.0143 - val_accuracy: 0.9992👉 5번째 epoch가 accuracy가 1.0으로 가장 높다가 또 다시 감소하는 형태를 보이고 있어, 5번째 epoch 모델을 불러와서 모델로 사용한다.

model05 = tf.keras.models.load_model('n05')👉 컴퓨터에 저장된 5번째 모델을 채택
다층신경망 : Multi-layer perceptrion
단순한 분류는 한 개의 Dense 층이라도 잘 계산을 하여 데이터의 특성을 잘 찾아 내겠지만, 문제는 분류의 갯수가 많고 특성을 찾아내는 데 선형적 만으로는 계산할 수 없고 복잡하다면 계산을 쪼갤 필요가 있다. 그래서 Dense 층이 더 많아지게 되는데 마지막 출력층 Dense를 제외한 나머지 중간에 있는 층을 은닉층이라고 부른다. 즉 이것이 다층으로 된 신경망이 되겠다.
다층신경망은 입력층(input layer), 은닉층(hidden leayer), 출력층(output layer) 순으로 구성된다. 은닉층에는 여러 개의 레이어가 들어갈 수 있는데 형태에는 제약이 없다. 그래서 좋은 성능을 내는 다양한 조합을 시도가 가능하다.
to_flatten = tf.keras.layers.Flatten()
to_hidden_layer = tf.keras.layers.Dense(16, activation = 'relu') # 은닉층
to_final_layer = tf.keras.layers.Dense(1, activation = 'sigmoid') # 출력층
model = tf.keras.Sequential([to_flatten, to_hidden_layer, to_final_layer])
model.compile(loss='binary_crossentropy', metrics=['accuracy'])
model.fit(x_train2,
y_train2,
epochs = 5,
validation_split = 0.1,
callbacks = [tf.keras.callbacks.ModelCheckpoint('n{epoch}')])Epoch 1/5
348/357 [============================>.] - ETA: 0s - loss: 0.4496 - accuracy: 0.9916INFO:tensorflow:Assets written to: n1\assets
357/357 [==============================] - 2s 4ms/step - loss: 0.4456 - accuracy: 0.9918 - val_loss: 5.4191e-16 - val_accuracy: 1.0000
Epoch 2/5
356/357 [============================>.] - ETA: 0s - loss: 0.0611 - accuracy: 0.9983INFO:tensorflow:Assets written to: n2\assets
357/357 [==============================] - 1s 4ms/step - loss: 0.0611 - accuracy: 0.9983 - val_loss: 2.5030e-16 - val_accuracy: 1.0000
Epoch 3/5
347/357 [============================>.] - ETA: 0s - loss: 0.0190 - accuracy: 0.9994INFO:tensorflow:Assets written to: n3\assets
357/357 [==============================] - 1s 4ms/step - loss: 0.0185 - accuracy: 0.9994 - val_loss: 8.0053e-08 - val_accuracy: 1.0000
Epoch 4/5
347/357 [============================>.] - ETA: 0s - loss: 0.0084 - accuracy: 0.9997INFO:tensorflow:Assets written to: n4\assets
357/357 [==============================] - 1s 4ms/step - loss: 0.0082 - accuracy: 0.9997 - val_loss: 2.1982e-14 - val_accuracy: 1.0000
Epoch 5/5
343/357 [===========================>..] - ETA: 0s - loss: 0.0088 - accuracy: 0.9996INFO:tensorflow:Assets written to: n5\assets
357/357 [==============================] - 1s 4ms/step - loss: 0.0131 - accuracy: 0.9995 - val_loss: 0.0281 - val_accuracy: 0.9984
다층신경망을 시각적으로 경험해 볼 수 있게 텐서플로 사이트에서 제공하는 딥러닝 시뮬레이션에 가보자.
🎲 분류 딥러닝 시뮬레이션
Tensorflow — Neural Network Playground
Tinker with a real neural network right here in your browser.
playground.tensorflow.org
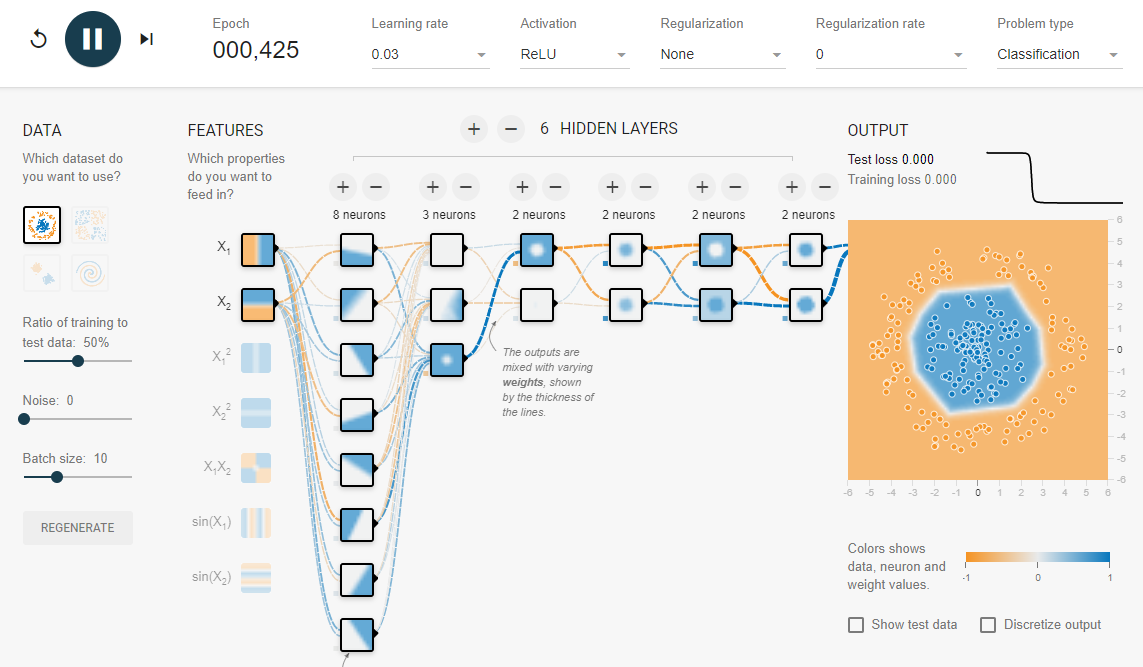
레이어층을 많게 늘려 가거나 각 층의 뉴런 갯수를 조절해 가면서 맨 오른쪽 사진에서 데이터가 두가지 경계로 분류를 잘 하는지 시뮬레이션을 할 수가 있다. 뉴런수가 많거나 층이 많아지면 속도는 느려질 수 있으나 정교하게 분류를 해 나갈 수 있을 볼 수 있다. 그렇게 되면 맨 왼쪽에 features항목에서 선형식을 사용해도 문제가 없다. 하지만 층이 별로 없으면 선형식 뿐만 아니라 비선형식을 사용하면 분류가 잘 됨을 볼 수 있다. 그렇지만 속도가 느려지기 때문에 시작을 선형적으로 하고 레이어를 적당히 늘려가는 것이 좋다고 본다.
다층신경망의
다항분류(multi-class classification)
• 이미지 데이터는 0~255로 밝기가 표현된다.
• 신경망에서 사용하는 시그모이드 등의 함수는 지나치게 큰 값이 들어오면 경사가 0에 가까워져서 학습이 잘 되지 않기 때문에 255로 나눠서 0~1 범위로 재조정해 준다.
x_train = x_train / 255
x_test = x_test / 255
✅ sigmoid Function (시그모이드 함수)
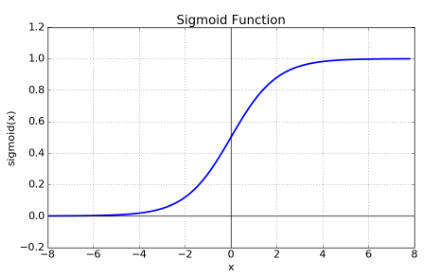

Zero-centered란 그래프의 중심 0인 형태로 함수값이 양수 혹은 음수에만 치우치지 않고 실수 전체에서 나타나는 형태를 의미한다. Sigmoid는 위의 그래프에서도 볼 수 있듯이 함수값이 항상 0보다 크거나 같은 형태로 나타난다. Neural networks에서 input은 이전 layer의 결과값으로 볼 수 있다. 그런데 sigmoid 함수는 항상 양수이기에 sigmoid를 한번 거친 이후 input 값은 항상 양수가 된다. 그렇게 되면 backpropagation을 할 때 문제가 생긴다.
print(tf.nn.sigmoid(1.0))
print(tf.nn.sigmoid(-1.0))
print(tf.nn.sigmoid(1.0) + tf.nn.sigmoid(-1.0))tf.Tensor(0.7310586, shape=(), dtype=float32)
tf.Tensor(0.26894143, shape=(), dtype=float32)
tf.Tensor(1.0, shape=(), dtype=float32)> 시그모이드함수는 모든 값을 0~1 사이값으로 출력하여 확률과 같이 만든다.
✅ ReLU Function : 렐루 함수
[렐루 함수 탄생 배경]
시그모이드(sigmoid) 함수는 X축 양쪽 끝으로 가면 포화(Saturation)가 되어 경사가 0에 가까워 진다. 다층신경망은 역전파 알고리즘(Back Propagation Algorithm)을사용하여 학습하기 때문에 minus 값이 존재하게 된다. 그러나 시그모이드 함수는 한상 plus값만 출력하기 때문에 이것이 판단에 문제가 된다. 출력값이 항상 plus이므로 경사가 한 방향으로만 생기게 되는 것이다. 또한 은닉층(hidden layers)의 경사가 0에 가까워지면, 이전 은닉층들의 학습이 잘 이뤄지지 않는 Gradient Vanishing(사라지는 경사) 문제가 발생한다.
Gradient Vanishing : 사라지는 경사 문제
다층 레이어의 중간 레이어에 그래디언트 에러가 역전파로 전달된다. 그런데 그래디언트는 '에러의 미분값'이기 때문에 전달함수도 미분값으로 전달하게 된다. 이렇게 되면 전달함수가 0, 1의 값을 제대로 전달하지 못하는 현상이 발생한다. 그래서 ReLU 전달함수가 등장하게 되었다. Rectified Linear Unit : ReLU에서 rectify는 정류하다, 수정하다라는 의미로 기존에 역전파 전달되던 값을 살리기 위해서 음수값이든 양수값이든 상관없이 항상 0~1사이의 양수로 출력하던 것을 음수값과 양수값을 다른 영역으로 출력이 되도록 수정을 한 것이다. 즉, 전달함수를 살리면서 에러도 역전파로 잘 전달할 수 있게 한 것이다.

※ ReLu 활성함수 개선 관련 논문예시 : Searching for Activation Functions
https://arxiv.org/pdf/1710.05941.pdf
Tanh (Hyperbolic Tangent function)
출력이 항상 0~1사이의 양수값으로 출력되는 것을 영역을 바꿔서 -1~1사이로 구분해서 출력하게 해주는 방법이다. 쌍곡선 탄젠트 함수는 음수값이 들어오면 음수로 전달하고 양수값이 들어오면 양수로 구분해서 전달하게 한다. 렐루함수와 같은 효과가 나타난다.
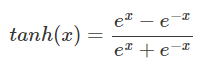

Softmax
소프트맥스 함수는 input값을 [0,1] 사이의 값으로 모두 정규화하여 출력하며, 출력값들의 총합은 항상 1이 되는 특성을 가진 함수이다. 다중분류(multi-class classification) 문제에서 사용한다. 분류될 클래스가 n개라고 할 때, n차원의 벡터를 입력받아 각 클래스에 속할 확률을 추정한다. 확률값을 반환한다는 점에서 시그모이드와 비슷하지만, 시그모이드 함수를 통과해 얻은 확률값들은 서로 독립적이다. 가령 3개의 클래스가 있다고 하면, 데이터 포인트가 클래스 1에 속할 확률은 다른 두 클래스의 확률을 고려하지 않는다. 따라서 multi-class classification에서 시그모이드 함수는 사용할 수 없고, 대신 소프트맥스 함수를 사용한다.
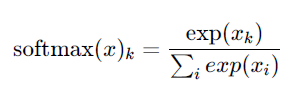
입력 받은 모든 값을 각각 0~1 범위로 변환하여 출력하고 출력값의 합은 1이 된다.
• 둘 중에 하나로 예측할 때 : sigmoid
• 셋 이상 중에 하나로 예측할 때 : softmax
▣ sigmoid와 softmax의 역할과 언제 사용하는가?
Dense의 결과가 각각의 점수가 다양하게 배출되는데, 이 숫자를 0~1의 범위의 확률로 다시 바꿔주는 역할을 한다. sigmoid는 이항분류에 사용하고 softmax는 다항분류에 사용한다. 그래서 sigmoid는 Dense(1)이 되고, softmax는 Dense(n)이 되게 된다.
tf.nn.softmax([1.0,2.0,3.0])<tf.Tensor: shape=(3,), dtype=float32, numpy=array([0.09003057, 0.24472848, 0.66524094], dtype=float32)>> 0.09003057 + 0.24472848 + 0.66524094 = 1
> 소프트맥스는 여러가지 다항의 요소들을 모두 합해서 1로 만드는 함수
to_flatten = tf.keras.layers.Flatten()
to_hidden_layer = tf.keras.layers.Dense(64, activation='relu')
to_final_layer = tf.keras.layers.Dense(10, activation='softmax') # 숫자가 10종류
model = tf.keras.Sequential([to_flatten, to_hidden_layer, to_final_layer])
model.compile(loss='sparse_categorical_crossentropy', metrics=['accuracy'])
model.fit(x_train,
y_train,
epochs = 5,
validation_split = 0.1,
callbacks = [tf.keras.callbacks.EarlyStopping()])Epoch 1/5
1688/1688 [==============================] - 5s 3ms/step - loss: 0.3122 - accuracy: 0.9118 - val_loss: 0.1496 - val_accuracy: 0.9573
Epoch 2/5
1688/1688 [==============================] - 5s 3ms/step - loss: 0.1591 - accuracy: 0.9538 - val_loss: 0.1235 - val_accuracy: 0.9630• sparse_categorical_crossentropy : 교차 엔트로피 (범주가 여러 개일 때)
'Python' 카테고리의 다른 글
| Confusion Matrix(혼동행렬) 생성 : MNIST로 생성한 모델 예측결과 판단 (0) | 2022.07.12 |
|---|---|
| Teachable Machine을 이용한 딥러닝 모델 생성 방법 (0) | 2022.07.12 |
| 컴퓨터 비전 데이터 분석 4가지 항목 (0) | 2022.07.12 |
| PIL과 OpenCV를 활용한 간단한 이미지 데이터 처리방법 (0) | 2022.07.04 |
| Understanding ML & DL in python (0) | 2022.06.07 |



